

Главная → База знаний → Настройка и администрирование → Распознавание картинок в 1С:Документооборот
Каким образом работает распознавание картинок в 1С:Документооборот?
В статье "Извлечение текстов в 1С:Документооборот" сказано, что 1С:Документооборот 8 умеет извлекать тексты из популярных офисных форматов файлов и использовать эту информацию для полнотекстового поиска по содержимому файлов. А вот если в СЭД помещен файл графического формата, то как получить распознанный текст из картинки?
В данной статье пойдет речь о том, какие надо установить дополнительные программы на сервер 1С, чтобы работало автоматическое распознавание сканов файлов.
Настройка распознавания изображений в 1С:Документооборот в клиент-серверном варианте на живых примерах подробно рассмотрена в видеокурсе.
Работа сканирования и распознавания в 1С:Документооборот 8 возможна только под Windows.
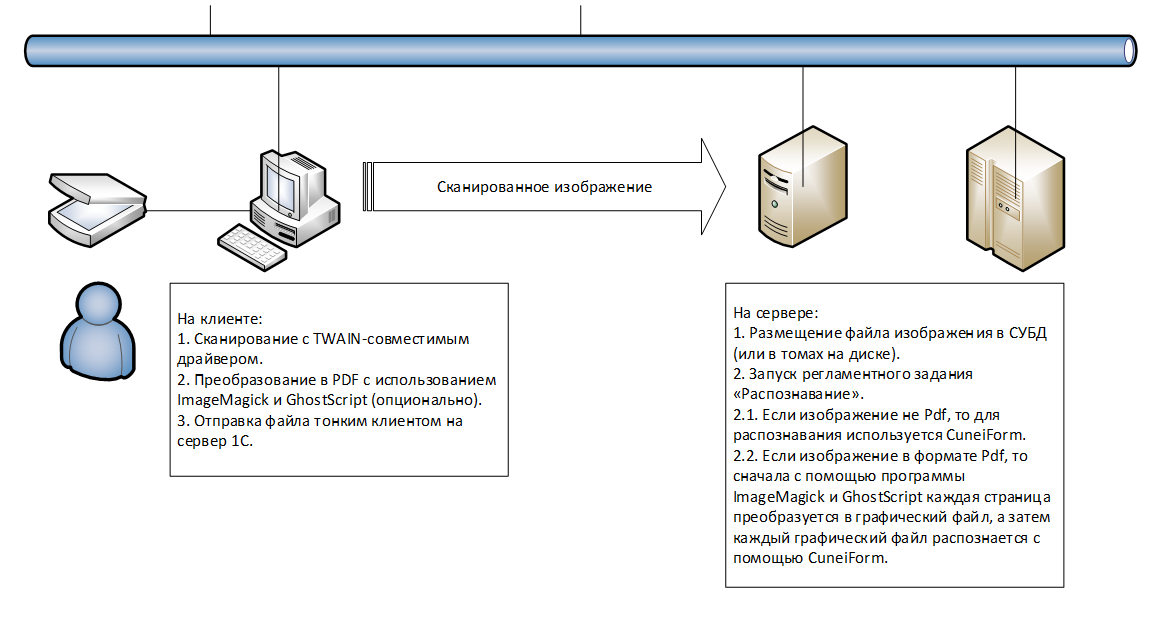
Чтобы настроить распознавание изображений на сервере нужно:
1. Установить программы CuneiForm, ImageMagic и Ghostscript.
2. Задать в настройках программы параметры распознавания и указать путь к программе ImageMagic.
Общая схема работы сканирования и распознавания указана на следующем рисунке.
Установка CuneiForm
Программа CuneiForm нужна для распознавания графических файлов.
Находим в дистрибутиве cuneiform файл setup.exe. Запускаем его и устанавливаем.
Загрузим любую картинку с текстом.
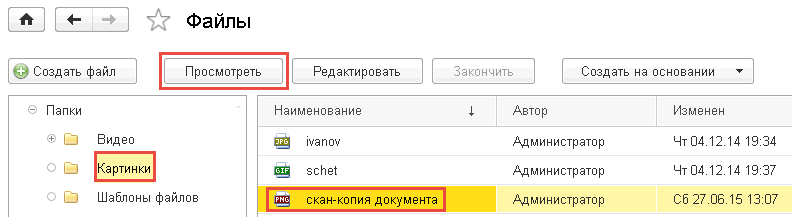
Откроем ее на просмотр и убедимся, что там есть текст.

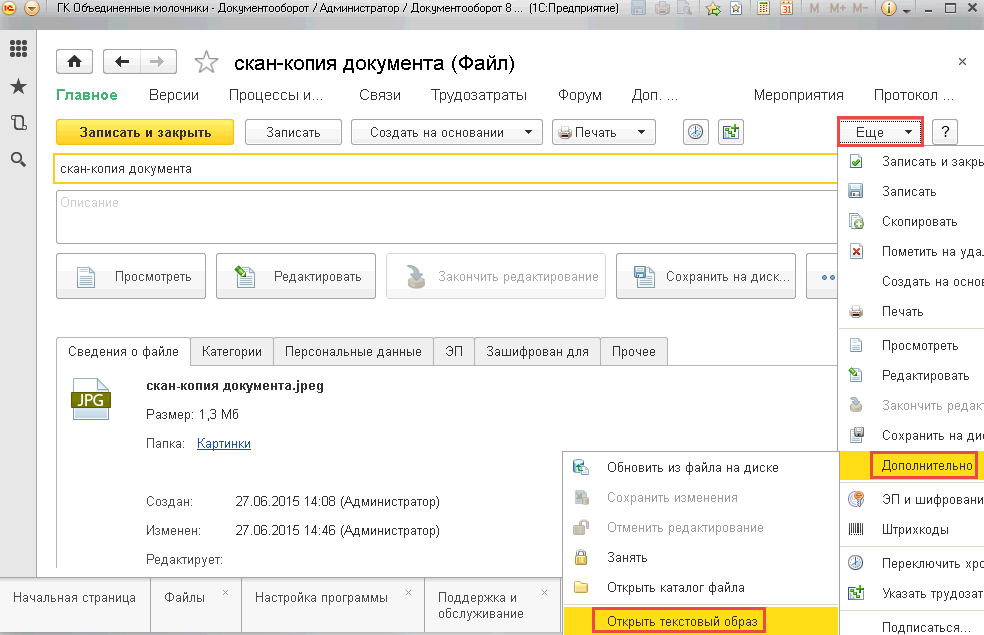
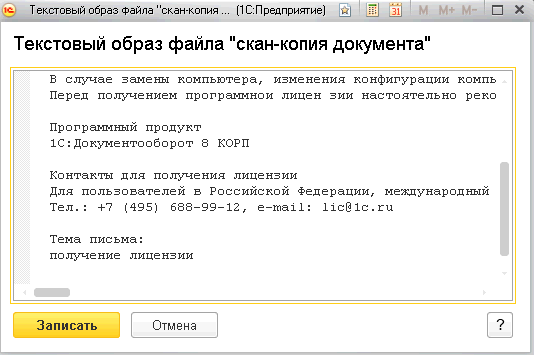
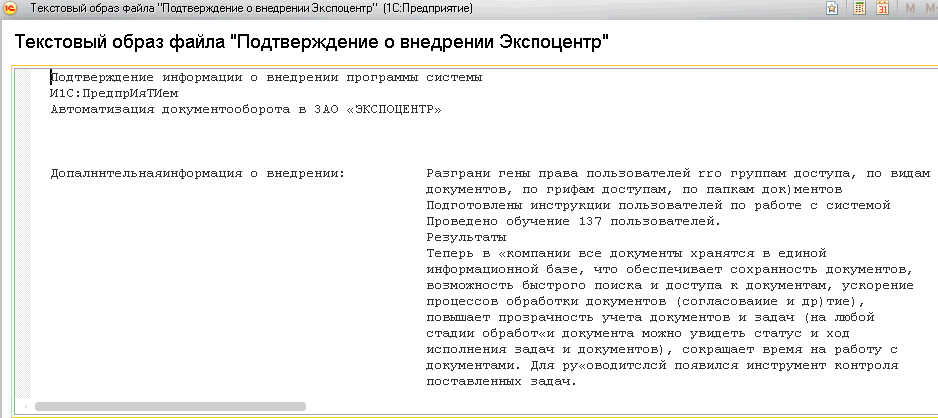
После отработки регламентного задания «Распознавание» увидим распознанный текст в текстовом образе.
Откроем теперь тестовый образ из карточки файла.
Установка Ghostscript
Программа Ghostscript нужна программе ImageMagic для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве Ghostscript файл gs901w32.exe. Запускаем его.
Указываем путь установки и нажимаем кнопку Install.
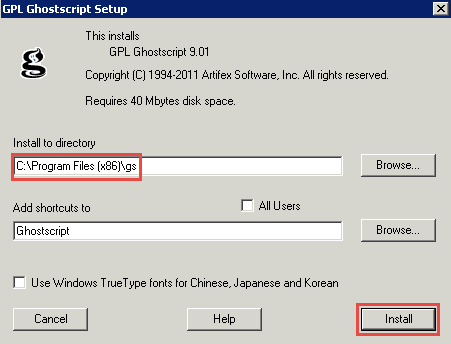
Программа установлена.
Установка ImageMagic
Программа ImageMagic нужна для преобразования графических файлов в формат pdf и обратно.
Находим в дистрибутиве ImageMagic файл ImageMagick-6.9.1-6-Q8-x86-dll.exe. Запускаем его.
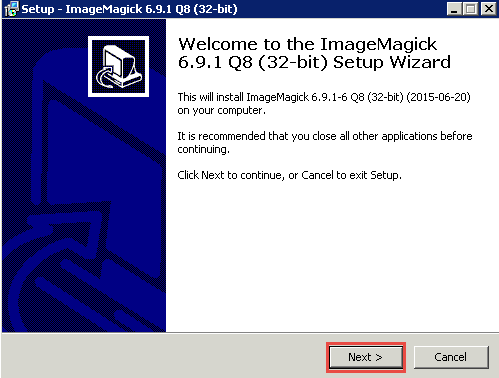
Соглашаемся с условиями лицензионного соглашения.
Читаем полезную информацию.
Указываем путь установки.
Указываем название папки стартового меню.
Указываем компоненты, которые надо установить.
Подтверждаем установку. Нажимаем кнопку Install.
Читаем полезную информацию.
Программа установлена. Нажимаем кнопку Finish.
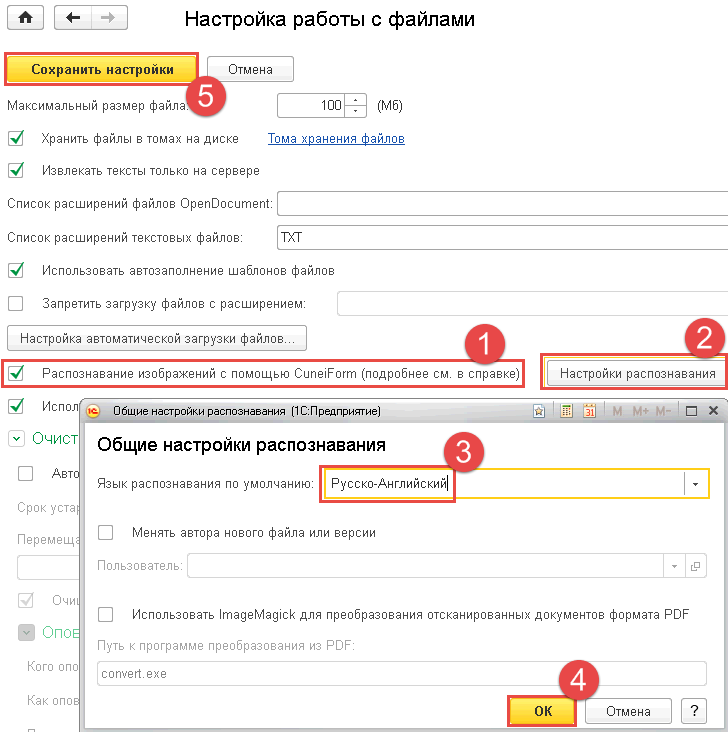
Теперь, чтобы на сервере 1С происходило преобразование отсканированных pdf-файлов в графические файлы с последующим распознаванием нам надо указать общие настройки распознавания.
В программе 1С:Документооборот в настройках программы нажимаем на кнопку «Настройки распознавания», включаем использование ImageMagick и указываем путь к программе.
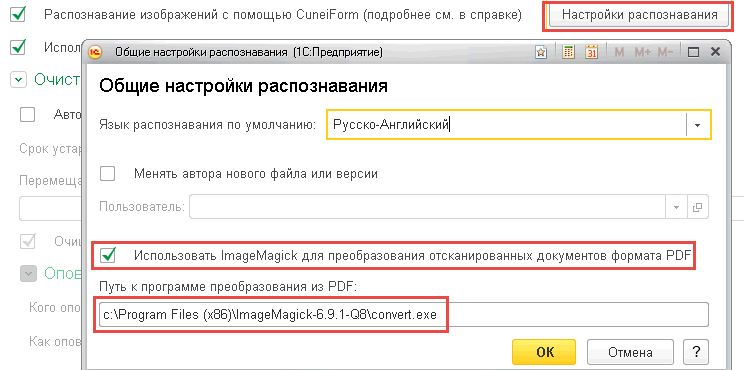
После того, как отработает регламентное задание «Распознавание» мы в текстовом образе увидим распознанный текст.
Настройка распознавания изображений в 1С:Документооборот в клиент-серверном варианте на живых примерах подробно рассмотрена в видеокурсе.




авторизуйтесь